Load the Data
library(tidyverse)
#> ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
#> ✔ ggplot2 3.4.0 ✔ purrr 1.0.1
#> ✔ tibble 3.1.8 ✔ dplyr 1.0.10
#> ✔ tidyr 1.2.1 ✔ stringr 1.5.0
#> ✔ readr 2.1.3 ✔ forcats 0.5.2
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
library(covdata)
#>
#> Attaching package: 'covdata'
#>
#> The following object is masked from 'package:datasets':
#>
#> uspop
library(ggrepel)Data for the United States come from a variety of sources:
- State-level case and mortality data for the United States from the COVID Tracking Project.
- State-level and county-level case and mortality data for the United States from the New York Times.
- Data from the US Centers for Disease Control’s Coronavirus Disease 2019 (COVID-19)-Associated Hospitalization Surveillance.
- State- and national-level reports from the United States National Center for Health Statistics.
COVID Tracking Project data
covus
#> # A tibble: 664,960 × 7
#> date state fips data_quality_grade measure count measu…¹
#> <date> <chr> <chr> <lgl> <chr> <dbl> <chr>
#> 1 2021-03-07 AK 02 NA positive 56886 Positi…
#> 2 2021-03-07 AK 02 NA probable_cases NA Probab…
#> 3 2021-03-07 AK 02 NA negative NA Negati…
#> 4 2021-03-07 AK 02 NA pending NA Pendin…
#> 5 2021-03-07 AK 02 NA hospitalized_current… 33 Curren…
#> 6 2021-03-07 AK 02 NA hospitalized_cumulat… 1293 Cumula…
#> 7 2021-03-07 AK 02 NA in_icu_currently NA Curren…
#> 8 2021-03-07 AK 02 NA in_icu_cumulative NA Cumula…
#> 9 2021-03-07 AK 02 NA on_ventilator_curren… 2 Curren…
#> 10 2021-03-07 AK 02 NA on_ventilator_cumula… NA Cumula…
#> # … with 664,950 more rows, and abbreviated variable name ¹measure_labelDraw a log-linear graph of cumulative reported US cases.
## Which n states are leading the count of positive cases or deaths?
top_n_states <- function(data, n = 5, measure = c("positive", "death")) {
meas <- match.arg(measure)
data %>%
group_by(state) %>%
filter(measure == meas, date == max(date)) %>%
drop_na(count) %>%
ungroup() %>%
top_n(n, wt = count) %>%
pull(state)
}
state_cols <- c("gray70", "#195F90FF", "#D76500FF", "#238023FF", "#AB1F20FF", "#7747A3FF",
"#70453CFF", "#D73EA8FF", "#666666FF", "#96971BFF", "#1298A6FF", "#6F9BD6FF",
"#FF952DFF", "#66CF51FF", "#FF4945FF", "#A07DBAFF", "#AC7368FF", "#EF69A2FF",
"#9F9F9FFF", "#CACA56FF", "#61C3D5FF")
covus %>%
group_by(state) %>%
mutate(core = case_when(state %nin% top_n_states(covus) ~ "",
TRUE ~ state),
end_label = ifelse(date == max(date), core, NA)) %>%
arrange(date) %>%
filter(measure == "positive", date > "2020-03-09") %>%
ggplot(aes(x = date, y = count, group = state, color = core, label = end_label)) +
geom_line(size = 0.5) +
geom_text_repel(segment.color = NA, nudge_x = 0.2, nudge_y = 0.1) +
scale_color_manual(values = state_cols) +
scale_x_date(date_breaks = "1 month", date_labels = "%b" ) +
scale_y_continuous(trans = "log2",
labels = scales::comma_format(accuracy = 1),
breaks = 2^c(seq(1, 22, 1))) +
guides(color = "none") +
labs(title = "COVID-19 Cumulative Recorded Cases by US State",
subtitle = paste("Data as of", format(max(covus$date), "%A, %B %e, %Y")),
x = "Date", y = "Count of Cases (log 2 scale)",
caption = "Data: COVID Tracking Project, http://covidtracking.com | Graph: @kjhealy") +
theme_minimal()
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
#> ℹ Please use `linewidth` instead.
#> Warning: Transformation introduced infinite values in continuous y-axis
#> Transformation introduced infinite values in continuous y-axis
#> Warning: Removed 22 rows containing missing values (`geom_line()`).
#> Warning: Removed 20242 rows containing missing values
#> (`geom_text_repel()`).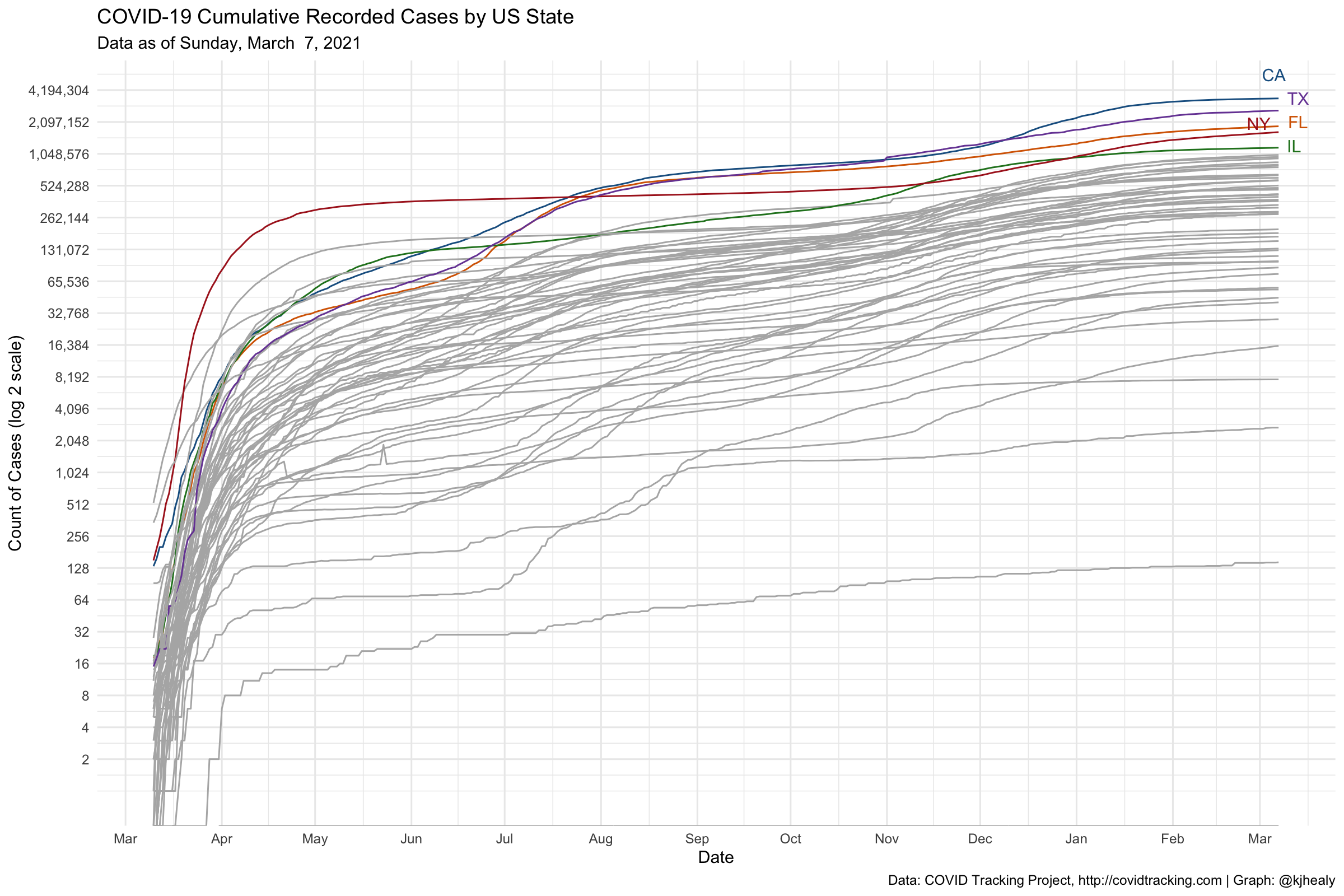
Calculating daily counts
The COVID Tracking Project reports cumulative counts for key measures such as positive tests and deaths. For example, for New York State:
measures <- c("positive", "death")
covus %>%
filter(measure %in% measures, state == "NY") %>%
select(date, state, measure, count) %>%
pivot_wider(names_from = measure, values_from = count)
#> # A tibble: 371 × 4
#> date state positive death
#> <date> <chr> <dbl> <dbl>
#> 1 2021-03-07 NY 1681169 39029
#> 2 2021-03-06 NY 1674380 38970
#> 3 2021-03-05 NY 1666733 38891
#> 4 2021-03-04 NY 1657777 38796
#> 5 2021-03-03 NY 1650184 38735
#> 6 2021-03-02 NY 1642480 38660
#> 7 2021-03-01 NY 1636680 38577
#> 8 2021-02-28 NY 1630445 38497
#> 9 2021-02-27 NY 1622865 38407
#> 10 2021-02-26 NY 1614724 38321
#> # … with 361 more rowsTo calculate daily counts from these cumulative measures, use lag().
covus %>%
filter(measure %in% measures, state == "NY") %>%
select(date, state, measure, count) %>%
pivot_wider(names_from = measure, values_from = count) %>%
mutate(across(positive:death, ~.x - lag(.x, order_by = date),
.names = "daily_{col}"))
#> # A tibble: 371 × 6
#> date state positive death daily_positive daily_death
#> <date> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 2021-03-07 NY 1681169 39029 6789 59
#> 2 2021-03-06 NY 1674380 38970 7647 79
#> 3 2021-03-05 NY 1666733 38891 8956 95
#> 4 2021-03-04 NY 1657777 38796 7593 61
#> 5 2021-03-03 NY 1650184 38735 7704 75
#> 6 2021-03-02 NY 1642480 38660 5800 83
#> 7 2021-03-01 NY 1636680 38577 6235 80
#> 8 2021-02-28 NY 1630445 38497 7580 90
#> 9 2021-02-27 NY 1622865 38407 8141 86
#> 10 2021-02-26 NY 1614724 38321 8204 94
#> # … with 361 more rowsDraw a graph of the weekly rolling average death rate, by state
state_pops <- uspop %>%
filter(sex_id == "totsex", hisp_id == "tothisp") %>%
select(state_abbr, statefips, pop, state) %>%
rename(name = state,
state = state_abbr, fips = statefips) %>%
mutate(state = replace(state, fips == "11", "DC"))
## Using a convenience function to do something similar
## to the lambda version above
get_daily_count <- function(count, date){
count - lag(count, order_by = date)
}
covus %>%
filter(measure == "death", state %in% unique(state_pops$state)) %>%
group_by(state) %>%
mutate(
deaths_daily = get_daily_count(count, date),
deaths7 = slider::slide_dbl(deaths_daily, mean, .before = 7, .after = 0, na.rm = TRUE)) %>%
left_join(state_pops) %>%
filter(date > lubridate::ymd("2020-03-15")) %>%
ggplot(mapping = aes(x = date, y = (deaths7/pop)*1e5)) +
geom_line(size = 0.5) +
scale_y_continuous(labels = scales::comma_format(accuracy = 1)) +
facet_wrap(~ name, ncol = 4) +
labs(x = "Date",
y = "Deaths per 100,000 Population (Seven Day Rolling Average)",
title = "Average Death Rate from COVID-19: US States and Washington, DC",
subtitle = paste("COVID Tracking Project data as of", format(max(covus$date), "%A, %B %e, %Y")),
caption = "Kieran Healy @kjhealy / Data: https://www.covidtracking.com/") +
theme_minimal()
#> Joining, by = c("state", "fips")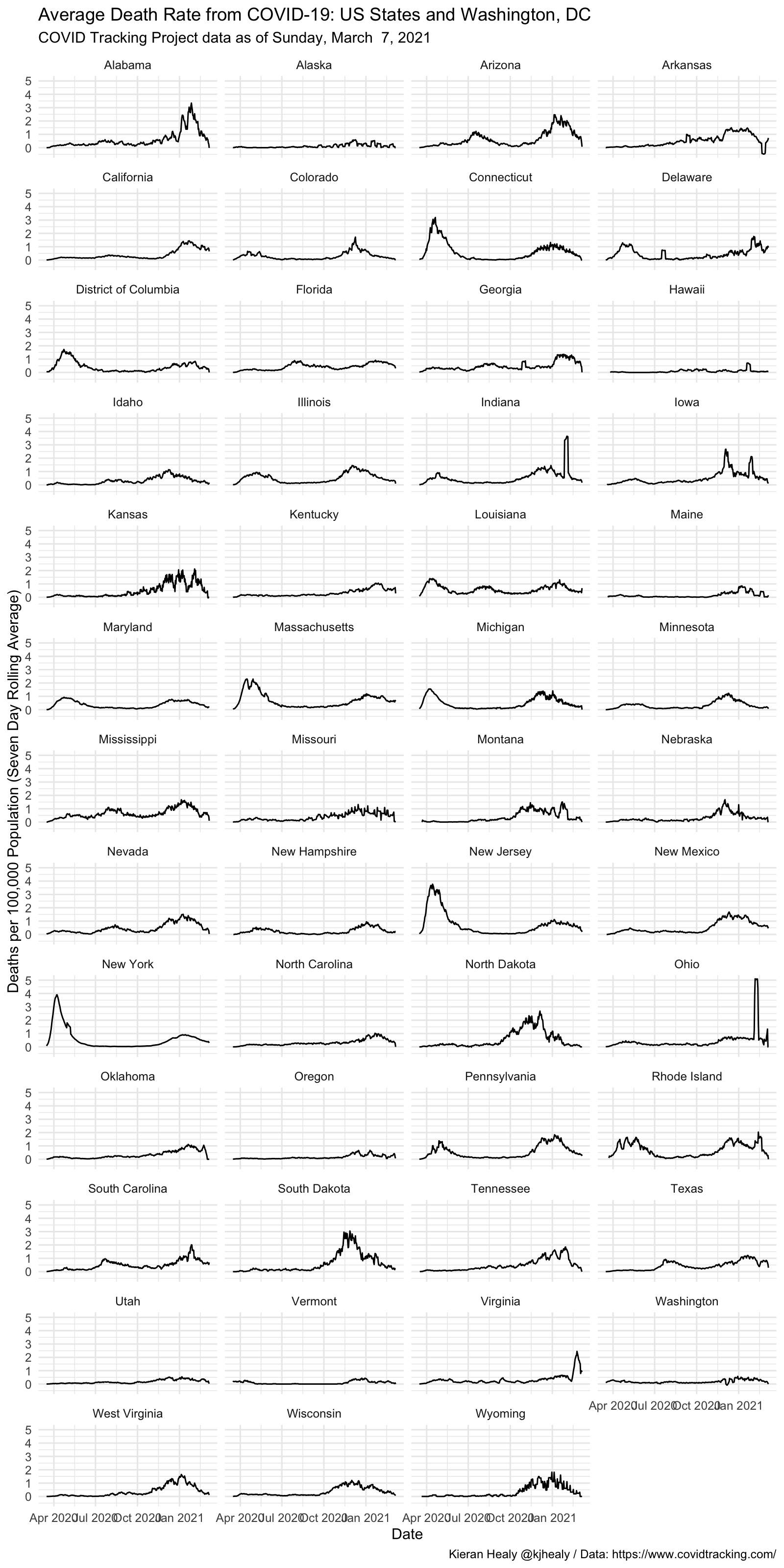
Draw a graph of the weekly rolling average death rate, by state, with free y-axes in the panels
covus %>%
filter(measure == "death", state %in% unique(state_pops$state)) %>%
group_by(state) %>%
mutate(
deaths_daily = get_daily_count(count, date),
deaths7 = slider::slide_dbl(deaths_daily, mean, .before = 7, .after = 0, na.rm = TRUE)) %>%
left_join(state_pops) %>%
filter(date > lubridate::ymd("2020-03-15")) %>%
ggplot(mapping = aes(x = date, y = (deaths7/pop)*1e5)) +
geom_line(size = 0.5) +
facet_wrap(~ name, ncol = 4, scales = "free_y") +
labs(x = "Date",
y = "Deaths per 100,000 Population (Seven Day Rolling Average)",
title = "Average Death Rate from COVID-19: US States and Washington, DC. Free scales.",
subtitle = paste("COVID Tracking Project data as of", format(max(covus$date), "%A, %B %e, %Y")),
caption = "Kieran Healy @kjhealy / Data: https://www.covidtracking.com/") +
theme_minimal()
#> Joining, by = c("state", "fips")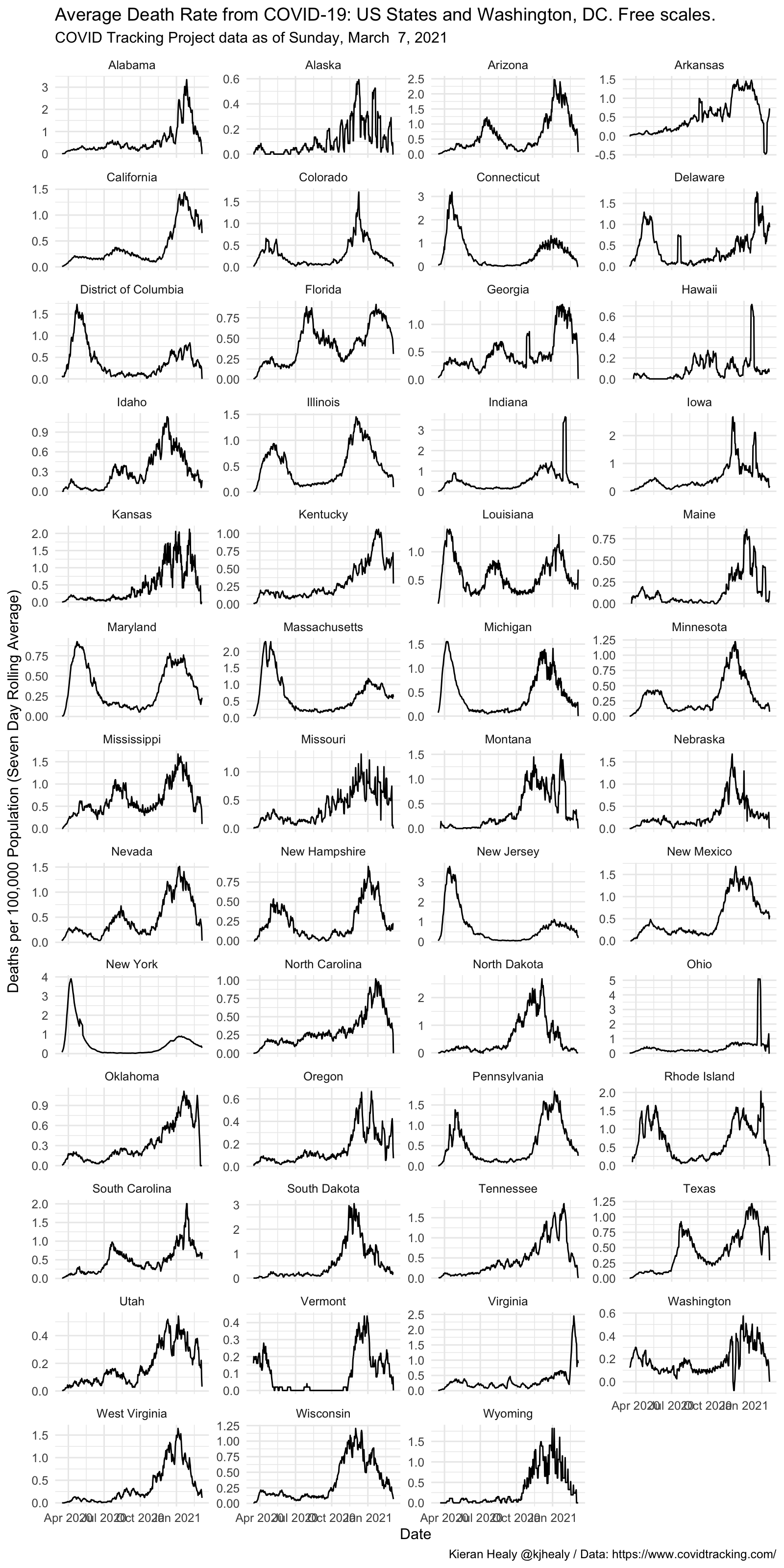
Draw a graph of cumulative reported US deaths, aggregated to the national level
covus %>%
filter(measure == "death") %>%
group_by(date) %>%
summarize(count = sum(count, na.rm = TRUE)) %>%
ggplot(aes(x = date, y = count)) +
geom_line(size = 0.75) +
scale_x_date(date_breaks = "3 months", date_labels = "%b %Y" ) +
scale_y_continuous(labels = scales::comma, breaks = seq(0, 500000, 100000)) +
labs(title = "COVID-19 Cumulative Recorded Deaths in the United States",
subtitle = paste("Data as of", format(max(covus$date), "%A, %B %e, %Y"), "Recorded counts underestimate total mortality."),
x = "Date", y = "Count of Deaths",
caption = "Data: COVID Tracking Project, http://covidtracking.com | Graph: @kjhealy") +
theme_minimal()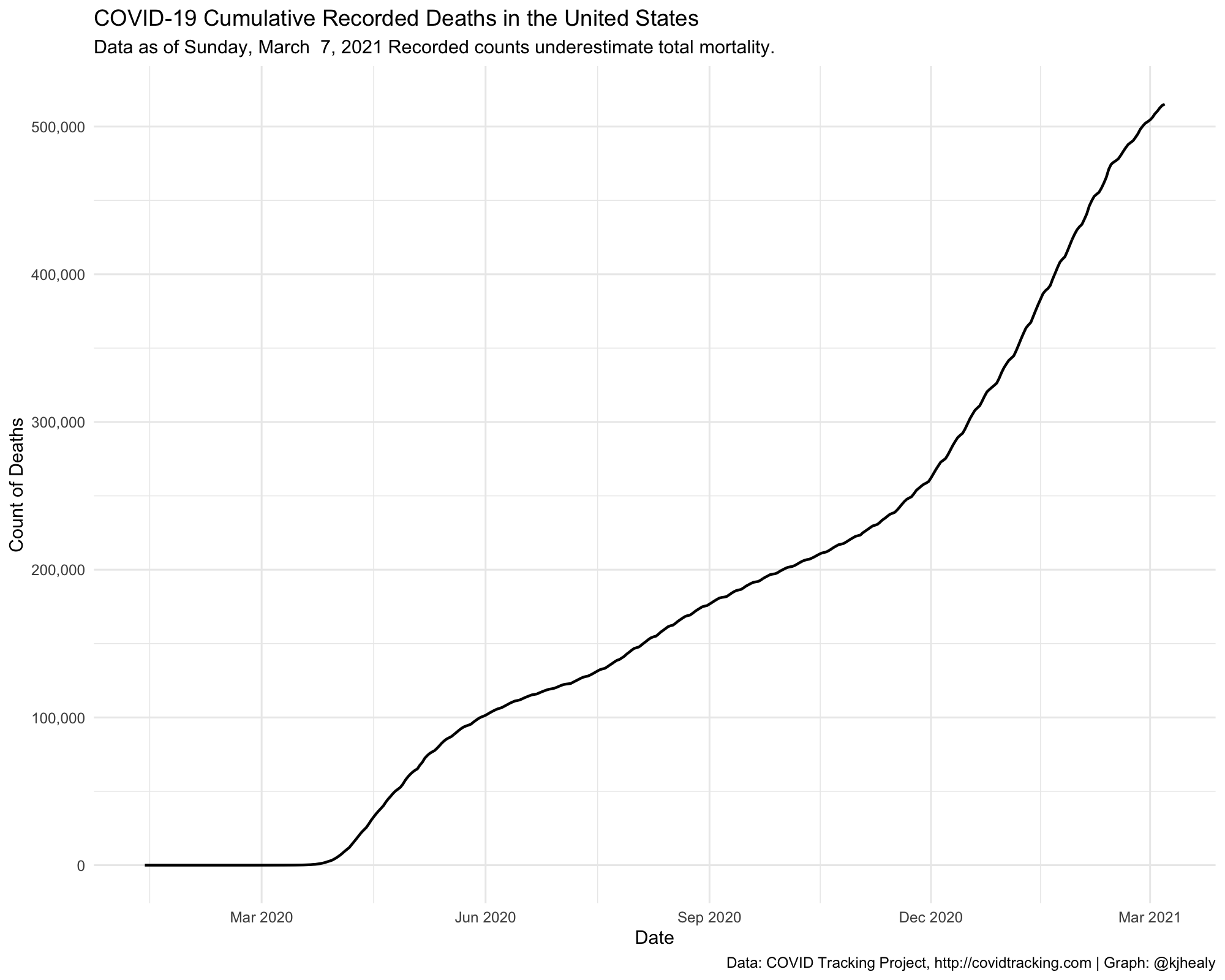
State-Level and County-Level (Cumulative) Data from the New York Times
State-level table
nytcovstate
#> # A tibble: 58,526 × 5
#> date state fips cases deaths
#> <date> <chr> <chr> <dbl> <dbl>
#> 1 2020-01-21 Washington 53 1 0
#> 2 2020-01-22 Washington 53 1 0
#> 3 2020-01-23 Washington 53 1 0
#> 4 2020-01-24 Illinois 17 1 0
#> 5 2020-01-24 Washington 53 1 0
#> 6 2020-01-25 California 06 1 0
#> 7 2020-01-25 Illinois 17 1 0
#> 8 2020-01-25 Washington 53 1 0
#> 9 2020-01-26 Arizona 04 1 0
#> 10 2020-01-26 California 06 2 0
#> # … with 58,516 more rowsCounty-level table
nytcovcounty
#> # A tibble: 2,502,832 × 6
#> date county state fips cases deaths
#> <date> <chr> <chr> <chr> <dbl> <dbl>
#> 1 2020-01-21 Snohomish Washington 53061 1 0
#> 2 2020-01-22 Snohomish Washington 53061 1 0
#> 3 2020-01-23 Snohomish Washington 53061 1 0
#> 4 2020-01-24 Cook Illinois 17031 1 0
#> 5 2020-01-24 Snohomish Washington 53061 1 0
#> 6 2020-01-25 Orange California 06059 1 0
#> 7 2020-01-25 Cook Illinois 17031 1 0
#> 8 2020-01-25 Snohomish Washington 53061 1 0
#> 9 2020-01-26 Maricopa Arizona 04013 1 0
#> 10 2020-01-26 Los Angeles California 06037 1 0
#> # … with 2,502,822 more rowsDraw a log-linear graph of cumulative cases by county in selected states.
We can see that data for some counties is either not available or hasn’t been correctly coded.
nytcovcounty %>%
filter(state %in% c("New York", "North Carolina", "Texas", "Florida", "California", "Illinois")) %>%
mutate(uniq_name = paste(county, state)) %>% # Can't use FIPS because of how the NYT bundled cities
group_by(uniq_name) %>%
mutate(days_elapsed = date - min(date)) %>%
ggplot(aes(x = days_elapsed, y = cases + 1, group = uniq_name)) +
geom_line(size = 0.25, color = "gray20") +
scale_x_continuous() +
scale_y_log10(labels = scales::label_number_si()) +
guides(color = "none") +
facet_wrap(~ state, ncol = 2) +
labs(title = "COVID-19 Cumulative Recorded Cases by US County",
subtitle = paste("New York is bundled into a single area in this data.\nData as of", format(max(nytcovcounty$date), "%A, %B %e, %Y")),
x = "Days since first case", y = "Count of Cases (log 10 scale)",
caption = "Data: The New York Times | Graph: @kjhealy") +
theme_minimal()
#> Warning: `label_number_si()` was deprecated in scales 1.2.0.
#> ℹ Please use the `scale_cut` argument of `label_number()` instead.