
The General Social Survey Cumulative Data (1972-2024, release 3) and Panel Data files packaged for easy use in R. The companion package to gssr is gssrdoc, which integrates the GSS codebook into R’s help system. I recommend you install both packages.
Installation
gssr is a data package, bundling several datasets into a convenient format. The relatively large size of the data in the package means it is not suitable for hosting on CRAN, the core R package repository. The same is true of {gssrdoc}.
Install via R-Universe
My R Universe provides binary packages for gssr and {gssrdoc}. To install both packages, copy and paste the following code to the R console:
# Install 'gssr' from 'ropensci' universe
install.packages('gssr', repos =
c('https://kjhealy.r-universe.dev', 'https://cloud.r-project.org'))
# Also recommended: install 'gssrdoc' as well
install.packages('gssrdoc', repos =
c('https://kjhealy.r-universe.dev', 'https://cloud.r-project.org'))Because the packages have dependencies that are on CRAN, we add CRAN as well as the R Universe to the repos argument.
The binary packages will install noticeably quicker than building the package from source. Plus, you can use install.packages() directly.
Install direct from GitHub
You can also install gssr from GitHub with:
remotes::install_github("kjhealy/gssr")Loading the data
library(gssr)
#> Package loaded. To attach the GSS data, type data(gss_all) at the console.
#> For the panel data and documentation, type e.g. data(gss_panel08_long) and data(gss_panel_doc).
#> For help on a specific GSS variable, type ?varname at the console.Single GSS years
You can get the data for any single GSS year by using gss_get_yr() to download it from NORC and put it directly into a tibble.
gss18 <- gss_get_yr(2018)
#> Fetching: https://gss.norc.org/documents/stata/2018_stata.zip
gss18
#> # A tibble: 2,348 × 1,144
#> year id wrkstat hrs1 hrs2 evwork wrkslf wrkgovt
#> <dbl+lbl> <dbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+l> <dbl+l>
#> 1 2018 1 3 [with … NA(i) [iap] 41 NA(i) [iap] 2 [som… 2 [pri…
#> 2 2018 2 5 [retir… NA(i) [iap] NA(i) [iap] 1 [yes] 2 [som… 2 [pri…
#> 3 2018 3 1 [worki… 40 NA(i) [iap] NA(i) [iap] 2 [som… 2 [pri…
#> 4 2018 4 1 [worki… 40 NA(i) [iap] NA(i) [iap] 2 [som… 2 [pri…
#> 5 2018 5 5 [retir… NA(i) [iap] NA(i) [iap] 1 [yes] 2 [som… 2 [pri…
#> 6 2018 6 5 [retir… NA(i) [iap] NA(i) [iap] 1 [yes] 2 [som… 2 [pri…
#> 7 2018 7 1 [worki… 35 NA(i) [iap] NA(i) [iap] 2 [som… 1 [gov…
#> 8 2018 8 1 [worki… 89 [89+… NA(i) [iap] NA(i) [iap] 2 [som… 2 [pri…
#> 9 2018 9 1 [worki… 40 NA(i) [iap] NA(i) [iap] 1 [sel… 2 [pri…
#> 10 2018 10 1 [worki… 40 NA(i) [iap] NA(i) [iap] 2 [som… 2 [pri…
#> # ℹ 2,338 more rows
#> # ℹ 1,136 more variables: occ10 <dbl+lbl>, prestg10 <dbl+lbl>,
#> # prestg105plus <dbl+lbl>, indus10 <dbl+lbl>, marital <dbl+lbl>,
#> # martype <dbl+lbl>, divorce <dbl+lbl>, widowed <dbl+lbl>,
#> # spwrksta <dbl+lbl>, sphrs1 <dbl+lbl>, sphrs2 <dbl+lbl>, spevwork <dbl+lbl>,
#> # cowrksta <dbl+lbl>, cowrkslf <dbl+lbl>, coevwork <dbl+lbl>,
#> # cohrs1 <dbl+lbl>, cohrs2 <dbl+lbl>, spwrkslf <dbl+lbl>, …The Cumulative Data File
The GSS cumulative data file is large. It is included ingssr but not loaded by default when you invoke the package. (That is, gssr does not use R’s “lazy loading” facility. The data file is too big to do this without error.) To load it (or the other) datasets, first load the library and then use data() to make the data available. For example, load the cumulative GSS file like this:
data(gss_all)This will take a moment. Once it is ready, the gss_all object is available to use in the usual way:
gss_all
#> # A tibble: 75,699 × 6,904
#> year id wrkstat hrs1 hrs2 evwork occ prestige
#> <dbl+lbl> <dbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl> <dbl+lb>
#> 1 1972 1 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 205 50
#> 2 1972 2 5 [retire… NA(i) [iap] NA(i) [iap] 1 [yes] 441 45
#> 3 1972 3 2 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 270 44
#> 4 1972 4 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 1 57
#> 5 1972 5 7 [keepin… NA(i) [iap] NA(i) [iap] 1 [yes] 385 40
#> 6 1972 6 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 281 49
#> 7 1972 7 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 522 41
#> 8 1972 8 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 314 36
#> 9 1972 9 2 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 912 26
#> 10 1972 10 1 [workin… NA(i) [iap] NA(i) [iap] NA(i) [iap] 984 18
#> # ℹ 75,689 more rows
#> # ℹ 6,896 more variables: wrkslf <dbl+lbl>, wrkgovt <dbl+lbl>,
#> # commute <dbl+lbl>, industry <dbl+lbl>, occ80 <dbl+lbl>, prestg80 <dbl+lbl>,
#> # indus80 <dbl+lbl>, indus07 <dbl+lbl>, occonet <dbl+lbl>, found <dbl+lbl>,
#> # occ10 <dbl+lbl>, occindv <dbl+lbl>, occstatus <dbl+lbl>, occtag <dbl+lbl>,
#> # prestg10 <dbl+lbl>, prestg105plus <dbl+lbl>, indus10 <dbl+lbl>,
#> # indstatus <dbl+lbl>, indtag <dbl+lbl>, marital <dbl+lbl>, …Integrated Help with gssrdoc
gssr’s companion package, gssrdoc provides documentation for all GSS variables in the cumulative data file via R’s help system. You can browse variables by name in the package’s help file or type ? followed by the name of the variable at the console to get a standard R help page containing information on the variable, the values it takes and (in most cases) a crosstabulation of the variable’s values for each year of the GSS. This facility is particularly convenient in an IDE such as RStudio or Microsoft Visual Studio.
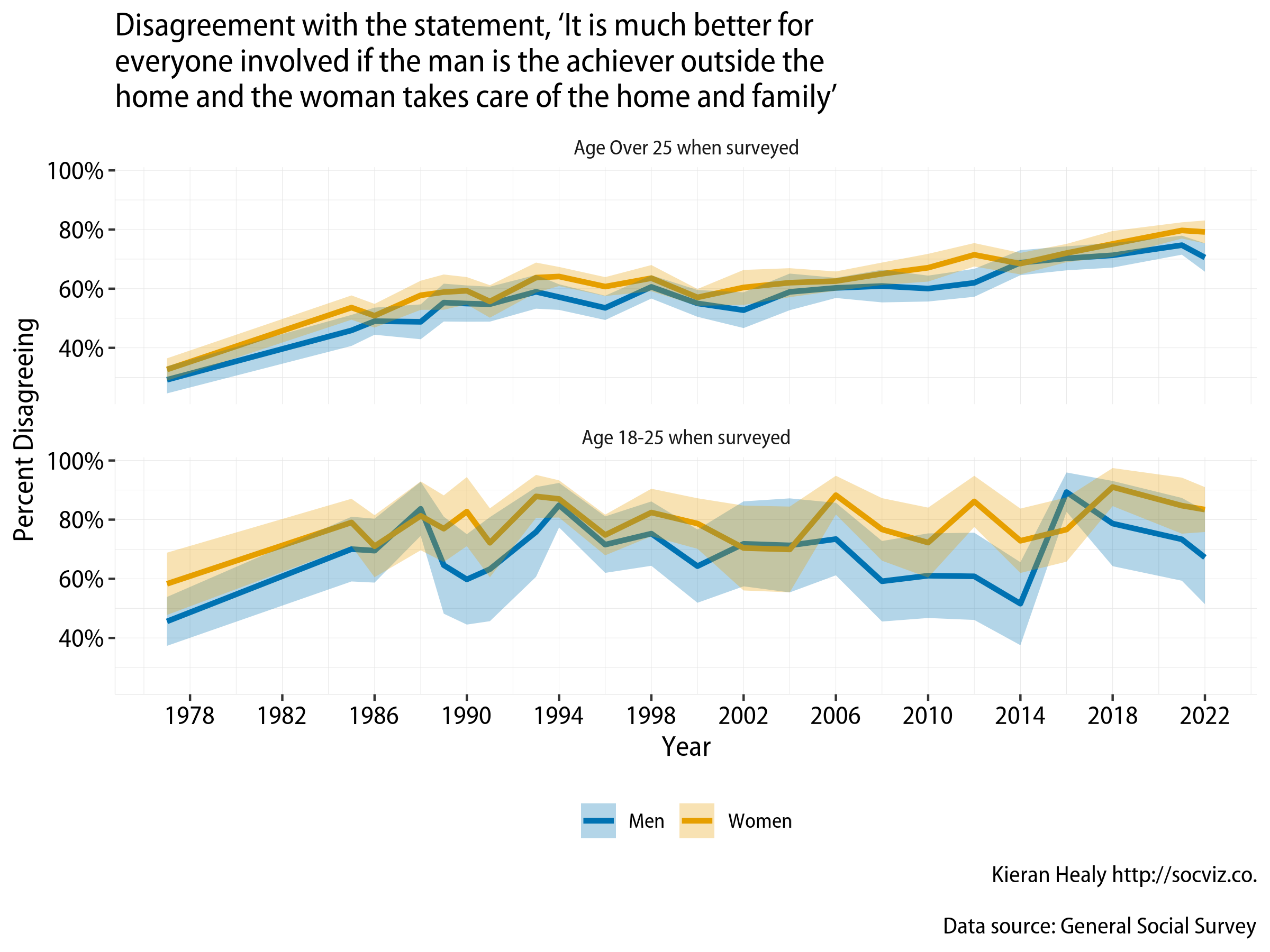
Which questions were asked in which years?
We often want to know which years a question or group of questions was asked. We can find this out for one or more variables with gss_which_years().
gss_which_years(gss_all, fefam)
#> # A tibble: 35 x 2
#> year fefam
#> <dbl> <lgl>
#> 1 1972 FALSE
#> 2 1973 FALSE
#> 3 1974 FALSE
#> 4 1975 FALSE
#> 5 1976 FALSE
#> 6 1977 TRUE
#> 7 1978 FALSE
#> 8 1980 FALSE
#> 9 1982 FALSE
#> 10 1983 FALSE
#> # … with 25 more rows
When querying more than one variable, use c():
gss_all |>
gss_which_years(c(industry, indus80, wrkgovt, commute)) |>
print(n = Inf)
# A tibble: 35 × 5
year industry indus80 wrkgovt commute
<dbl+lbl> <lgl> <lgl> <lgl> <lgl>
## 1972 TRUE FALSE FALSE FALSE
## 1973 TRUE FALSE FALSE FALSE
## 1974 TRUE FALSE FALSE FALSE
## 1975 TRUE FALSE FALSE FALSE
## 1976 TRUE FALSE FALSE FALSE
## 1977 TRUE FALSE FALSE FALSE
## 1978 TRUE FALSE FALSE FALSE
## 1980 TRUE FALSE FALSE FALSE
## 1982 TRUE FALSE FALSE FALSE
## 1983 TRUE FALSE FALSE FALSE
## 1984 TRUE FALSE FALSE FALSE
## 1985 TRUE FALSE TRUE FALSE
## 1986 TRUE FALSE TRUE TRUE
## 1987 TRUE FALSE FALSE FALSE
## 1988 TRUE TRUE FALSE FALSE
## 1989 TRUE TRUE FALSE FALSE
## 1990 TRUE TRUE FALSE FALSE
## 1991 FALSE TRUE FALSE FALSE
## 1993 FALSE TRUE FALSE FALSE
## 1994 FALSE TRUE FALSE FALSE
## 1996 FALSE TRUE FALSE FALSE
## 1998 FALSE TRUE FALSE FALSE
## 2000 FALSE TRUE TRUE FALSE
## 2002 FALSE TRUE TRUE FALSE
## 2004 FALSE TRUE TRUE FALSE
## 2006 FALSE TRUE TRUE FALSE
## 2008 FALSE TRUE TRUE FALSE
## 2010 FALSE TRUE TRUE FALSE
## 2012 FALSE FALSE TRUE FALSE
## 2014 FALSE FALSE TRUE FALSE
## 2016 FALSE FALSE TRUE FALSE
## 2018 FALSE FALSE TRUE FALSE
## 2021 FALSE FALSE FALSE FALSE
## 2022 FALSE FALSE FALSE FALSE
## 2024 FALSE FALSE FALSE FALSE Panel data
In addition to the Cumulative Data File, the gssr package also includes the GSS’s panel data. The current rotating panel design began in 2006. A panel of respondents were interviewed that year and followed up on for further interviews in 2008 and 2010. A second panel was interviewed beginning in 2008, and was followed up on for further interviews in 2010 and 2012. And a third panel began in 2010, with follow-up interviews in 2012 and 2014. The gssr package provides three datasets, one for each of three-wave panels. They are gss_panel06_long, gss_panel08_long, and gss_panel10_long. The datasets are provided by the GSS in wide format but (as their names suggest) they are packaged here in long format. The 2020 panel is an exception to this, for reasons described below. The conversion was carried out using the panelr package and its long_panel() function. Conversion from long back to wide format is possible with the tools provided in panelr.
The panel data objects must be loaded in the same way as the cumulative data file, using data().
data("gss_panel06_long")
gss_panel06_long
#> # A tibble: 6,000 × 1,572
#> firstid ballot form formwt oversamp sampcode sample samptype vstrat vpsu
#> <fct> <fct> <fct> <dbl> <dbl> <fct> <fct> <fct> <dbl> <dbl>
#> 1 0009 Ballot c Alter… 1 1 501 2000 … 2006 Sa… 1957 2
#> 2 0009 Ballot c Alter… 1 1 501 2000 … 2006 Sa… 1957 2
#> 3 0009 Ballot c Alter… 1 1 501 2000 … 2006 Sa… 1957 2
#> 4 0010 Ballot a Stand… 1 1 501 2000 … 2006 Sa… 1957 2
#> 5 0010 Ballot a Stand… 1 1 501 2000 … 2006 Sa… 1957 2
#> 6 0010 Ballot a Stand… 1 1 501 2000 … 2006 Sa… 1957 2
#> 7 0011 Ballot c Alter… 1 1 501 2000 … 2006 Sa… 1957 2
#> 8 0011 Ballot c Alter… 1 1 501 2000 … 2006 Sa… 1957 2
#> 9 0011 Ballot c Alter… 1 1 501 2000 … 2006 Sa… 1957 2
#> 10 0012 Ballot a Alter… 1 1 501 2000 … 2006 Sa… 1958 1
#> # ℹ 5,990 more rows
#> # ℹ 1,562 more variables: wtpan12 <dbl>, wtpan123 <dbl>, wtpannr12 <dbl>,
#> # wtpannr123 <dbl>, letin1a <fct>, wave <dbl>, abany <fct>, abdefect <fct>,
#> # abhlth <fct>, abnomore <fct>, abpoor <fct>, abrape <fct>, absingle <fct>,
#> # accntsci <fct>, acqasian <fct>, acqattnd <fct>, acqblack <fct>,
#> # acqbrnda <fct>, acqchild <fct>, acqcohab <fct>, acqcon <fct>,
#> # acqcops <fct>, acqdems <fct>, acqelecs <fct>, acqfmasn <fct>, …Panel data objects are regular tibbles. You do not need to use panelr to work with the data.
The column names in long format do not have wave identifiers. Rather, firstid and wave variables track the cases. The firstid variable is unique for every respondent in the panel and has no missing values. The wave variable indexes responses from a given firstid panelist in each wave (if observed). The id variable is from the GSS and indexes individuals within waves.
data("gss_panel08_long")
gss_panel08_long |>
select(firstid, wave, id, sex)
#> # A tibble: 6,069 × 4
#> firstid wave id sex
#> <fct> <dbl> <fct> <fct>
#> 1 0001 1 1 Male
#> 2 0001 2 8001 Male
#> 3 0001 3 <NA> <NA>
#> 4 0002 1 2 Male
#> 5 0002 2 8002 Male
#> 6 0002 3 8001 Male
#> 7 0003 1 3 Male
#> 8 0003 2 8003 Male
#> 9 0003 3 8002 Male
#> 10 0004 1 4 Male
#> # ℹ 6,059 more rowsWe can look at attrition across waves with, e.g.:
The 2020 Panel Data
The COVID-19 pandemic also affected the panel data design. In 2020, the GSS was run as two studies; namely, (1) a panel re-interview of past respondents from the 2016 and 2018 cross sectional GSS studies (referred to as the 2016-2020 GSS Panel), and (2) an independent fresh cross-sectional address-based sampling push to web study (referred to as 2020 cross-sectional survey). The gssr package provides the data for the first study as gss_panel20. This study empaneled former 2016 and 2018 GSS respondents to answer a GSS questionnaire in 2020 (i.e., the 2016-2020 GSS panel). In the 2016-2020 GSS Panel, variables only contain data from one of the three years. To differentiate between versions of each variable, they have been appended with suffixes. Variables from 2016 (Wave 1a) have _1a appended, variables from 2018 (Wave 1b) have _1b appended, and variables from 2020 (Wave 2) have _2 appended. Users can also track cases from 2016 and 2018, and reinterviews from 2020 with the variable samptype.
data("gss_panel20")
gss_panel20
#> # A tibble: 5,215 × 4,296
#> samptype yearid fileversion panstat wtssall_1a wtssall_1b wtssall_2
#> <dbl+lbl> <chr> <chr> <dbl+l> <dbl> <dbl> <dbl>
#> 1 2016 [sample from… 20160… GSS 2020 P… 1 [sel… 0.957 NA 1.09
#> 2 2016 [sample from… 20160… GSS 2020 P… 1 [sel… 0.478 NA 0.543
#> 3 2016 [sample from… 20160… GSS 2020 P… 0 [not… 0.957 NA NA
#> 4 2016 [sample from… 20160… GSS 2020 P… 1 [sel… 1.91 NA 2.17
#> 5 2016 [sample from… 20160… GSS 2020 P… 0 [not… 1.44 NA NA
#> 6 2016 [sample from… 20160… GSS 2020 P… 2 [sel… 0.957 NA NA
#> 7 2016 [sample from… 20160… GSS 2020 P… 0 [not… 1.44 NA NA
#> 8 2016 [sample from… 20160… GSS 2020 P… 1 [sel… 0.957 NA 1.09
#> 9 2016 [sample from… 20160… GSS 2020 P… 1 [sel… 0.957 NA 1.09
#> 10 2016 [sample from… 20160… GSS 2020 P… 0 [not… 0.957 NA NA
#> # ℹ 5,205 more rows
#> # ℹ 4,289 more variables: wtssnr_1a <dbl>, wtssnr_1b <dbl>, wtssnr_2 <dbl>,
#> # vstrat_1a <dbl>, vstrat_1b <dbl>, vstrat_2 <dbl>, vpsu_1a <dbl>,
#> # vpsu_1b <dbl>, vpsu_2 <dbl>, year_1a <int>, year_1b <int>, year_2 <int>,
#> # id_1a <dbl>, id_1b <dbl>, id_2 <dbl>, mar1_1a <dbl+lbl>, mar2_1a <dbl+lbl>,
#> # mar3_1a <dbl+lbl>, mar4_1a <dbl+lbl>, mar5_1a <dbl+lbl>, mar6_1a <dbl+lbl>,
#> # mar7_1a <dbl+lbl>, mar8_1a <dbl+lbl>, mar9_1a <dbl+lbl>, …Unlike the other panels, these data are provided in wide format. Users are strongly encouraged to read the official documentation at the NORC website.
Official GSS Documentation
The GSS Documentation Page contains links to extensive technical documentation for the survey, including the Codebook for the 1972-2024 R3 Cumulative File and What’s New in 2024 R3.
Further details
The package is documented at http://kjhealy.github.io/gssr/. The GSS homepage is at http://gss.norc.org/. While the gssr package incorporates the publicly-available GSS cumulative data file, this package is not associated with or endorsed by the National Opinion Research Center or the General Social Survey.